In the future, there may be even a dedicated panel in the Dashboard helping Perl developers. (Eddie?  ).
).
The basic design principles are the same: to provide libraries that allow a full object-oriented approach to BioMoby entities (data types and service instances) and shielding service developers from all XML wrappers and envelopes. The BioMoby entities are taken from the local cache, mirroring BioMoby registries, and thus allowing fast access to all needed details.
Because Perl allow more ways to do things (a freedom that one pays for by her own responsibility to do rather good than bad things) Perl Moses differs slightly from its Java brother - mainly by not insisting to create all necessary objects in advance but building them on-the-fly.
Table of Contents
However, before going to gory details, let's install Perl Moses and create and call the first service.
cd <somewhere> cvs -d :pserver:cvs@cvs.open-bio.org:/home/repository/moby login cvs -d :pserver:cvs@cvs.open-bio.org:/home/repository/moby co -P moby-live/Java cd <somewhere>/moby-live/Java ant installUnder Windows, the last command is build.bat (and some slashes become backslashes). More about building jMoby can be found here.
You do not need to do this step if you already have jMoby installed and built. In that case, do just (it will bring the latest version of Perl Moses):
cvs update -dP
cd <somewhere>/moby-live/Java/src/scripts ./install.plThis will also create/update your local cache of a BioMoby registry. Which may take several minutes when run the first time. There are more details about installation here.
cd <your-jmoby-home>/src/Perl ../scripts/generate-service samples.jmoby.net HelloBiomobyWorldIt creates a Perl module Service::HelloBiomobyWorld (in <your-jmoby-home>/src/Perl/services/), representing your first BioMoby Web Service . The service is empty - but is already able to accept BioMoby input requests and recognize its own data type, and it produces fake output data - but again, the output data are of the correct type (as registered for this service).
You can even generate more (or all) services for your authority:
../scripts/generate-service samples.jmoby.netMore about generating services in generating scripts and what Perl Moses does.
cd /usr/lib/cgi-bin sudo ln -s /home/senger/moby-live/Java/src/Perl/MobyServer.cgi .More about how to deploy your services, also in cases when you cannot make symbolic links, is in deploying.
../scripts/testing-service -e http://localhost/cgi-bin/MobyServer.cgi HelloBiomobyWorldOf course, you can also send real data, from a local file:
../scripts/testing-service -e http://localhost/cgi-bin/MobyServer.cgi \
HelloBiomobyWorld \
data/my-input.xml
An output (the same with any input data) is nothing really
exciting:
<?xml version="1.0"?>
<moby:MOBY xmlns:moby="http://www.biomoby.org/moby">
<moby:mobyContent moby:authority="samples.jmoby.net">
<moby:serviceNotes>
<moby:Notes>Response created at Sun Jul 30 12:24:49 2006 (GMT), by the service 'HelloBiomobyWorld'.</moby:Notes>
</moby:serviceNotes>
<moby:mobyData moby:queryID="job_0">
<moby:Simple moby:articleName="greeting">
<moby:String moby:id="" moby:namespace="">this is a value </moby:String>
</moby:Simple>
</moby:mobyData>
</moby:mobyContent>
</moby:MOBY>
You immediately notice that the returned value does not even have an
expected "hello" greeting but only a plain "this is a value". Well, a
fake output is just a fake output. You would need to add your own
business logic into you service to do something meaningful
(such as saying warmly "Hello, Biomoby"). But even with an empty input and fake output, you can see that the output knows about the HelloBiomobyWorld service (see the output type moby:String and the article name greeting, both coming from the registry knowledge). Also, the service provider can see few log entries:
2006/07/30 13:24:49 (673) INFO> [19345] (eval 127):92 - *** REQUEST START *** REMOTE_ADDR: 127.0.0.1, HTTP_USER_AGENT: SOAP::Lite/Perl/0.60, CONTENT_LENGTH: 736, HTTP_SOAPACTION: "http://biomoby.org/#HelloBiomobyWorld" 2006/07/30 13:24:49 (721) INFO> [19345] (eval 127):160 - *** RESPONSE READY ***The number in square brackets is a process ID - it helps to find which response belongs to which request when a site gets more to many requests in the same time. And in parenthesis, there is the number of milliseconds since the program has started. More about the log format in logging.
The same service can be called also using a jMoby command-line testing client:
cd <jmoby-home> build/run/run-service -service HelloBiomobyWorld \ -e http://localhost/cgi-bin/MobyServer.cgigiving the same results (this time, in a non-XML format):
Authority: samples.jmoby.net
Service notes: Response created at Fri Jul 28 10:35:34 2006 (GMT), by the service 'HelloBiomobyWorld'.
Jobs (invocations):
(1) Query ID: job_0
Data elements:
(Simple) Article name: greeting
MobyString
Value: this is a value
More about testing Perl Moses services is in clients.
An honest answer is "I do not know". Because I never wrote any BioMoby service based on CommonSubs.pl. As far as I know the CommonSubs.pl are good, reliable and used. I think (guessing), however, that Perl Moses allows few things that CommonSubs.pl have not aimed for:
In other words, the services written with the Perl Moses as their back-end are more unified and less prone to be changed when their environment changes. They should differ really only in their business logic (what they do, and not how they communicate with the rest of the world).
Having said that it is fair also to add that CommonSubs.pl have been used for a while so people already have found and fixed their bugs, a process Perl Moses has yet to come through.
And, of course, the greatest motivation comes from the spirit of the Perl slogan of TMTOWTDI, There's more than one way to do it.
In the future, there may be even a dedicated panel in the Dashboard helping Perl developers. (Eddie? ).
The other modules needed are (all available from the CPAN):
 To be expected
To be expectedIn order to start anything related to Perl Moses (except perhaps the script config-status.pl), you need to create, or update the cache. Take it as a requirement. The Perl Moses does not have own abilities to do that - but sharing the same local cache with Java and its programs, such as Dashboard, is a recommended way.
To be expected?Also, regarding the expected CPAN BioMoby Bundle mentioned elsewhere in this document, I plan to include there a snapshot of the default BioMoby registry - so the first touch with BioMoby will be, hopefully, without any delays.
The Java programs dealing with caching are available from jMoby. Make a CVS checkout first and then build everything (change slashes to backslashes on Windows):
cd moby-live/Java antThe user-friendliest way to create or update the cache is by using Dashboard. Or, you can do it from the command-line (<your-cache-directory> is any directory where you wish to have the cache):
build/run/run-cache-client -cachedir <your-cache-directory> -updateor
build/run/run-cache-client -cachedir <your-cache-directory> -fillWhen in doubts, you can always ask for help, or to check what is currently in the cache:
build/run/run-cache-client -h build/run/run-cache-client -cachedir <your-cache-directory> -infoYou need to tell Perl Moses (i.e. to tell your service implementation) where the cache is located. It is done through the configuration.
Okay. Having said all that, have you heard about The Law of Leaky Abstractions? Because - in case our abstraction does not leak - you can move the above to a lower rack in your memory, and let the Perl Moses installation script deal with the local cache. But - as the article says - It's good to know.
./install.plThis is an example of a typical conversation and output of the first installation:
senger@sherekhan:~/jMoby/src/scripts$ ./install.pl
Welcome, BioMobiers. Preparing stage for Perl MoSeS...
------------------------------------------------------
OK. Module FindBin is installed.
OK. Module SOAP::Lite is installed.
OK. Module XML::LibXML is installed.
OK. Module Log::Log4perl is installed.
OK. Module Template is installed.
OK. Module Config::Simple is installed.
OK. Module IO::Scalar is installed.
OK. Module IO::Prompt is installed.
Installing in /home/senger/moby-live/Java/src/scripts/../Perl
Created log file '/home/senger/moby-live/Java/src/scripts/../Perl/services.log'.
Created log file '/home/senger/moby-live/Java/src/scripts/../Perl/parser.log'.
Log properties file created: '/home/senger/moby-live/Java/src/scripts/../Perl/log4perl.properties'
Web Server file created: '/home/senger/moby-live/Java/src/scripts/../Perl/MobyServer.cgi'
Directory for local cache [/home/senger/moby-live/Java/src/scripts/../../myCache]
Local cache in '/home/senger/moby-live/Java/src/scripts/../../myCache'.
Should I try to fill or update the local cache [y]? y
What registry to use? [default]
a. IRRI
b. MIPS
c. default
d. iCAPTURE
e. testing
> a
Using registry: IRRI
(at http://cropwiki.irri.org/cgi-bin/MOBY-Central.pl)
The following command will be executed to update the cache:
/home/senger/moby-live/Java/src/scripts/../../build/run/run-cache-client
-e http://cropwiki.irri.org/cgi-bin/MOBY-Central.pl
-uri http://cropwiki.irri.org/MOBY/Central
-cachedir /home/senger/moby-live/Java/src/scripts/../../myCache -update
Updating local cache (it may take several minutes)...
Configuration file created: '/home/senger/moby-live/Java/src/scripts/../Perl/moby-services.cfg'
Done.
All these things can be done manually, at any time. Installation
script just makes it easier for the first comers. Here is what the
installation does:
I refer to the directory moby-live/Java/src/Perl as <pmoses-home>, and to the directory moby-live/Java as <jmoby-home>.
If you wish to install from the scratch (the same way it was done the first time), start it by using a force option:
./install.pl -FIn this mode, it overwrites files moby-services.cfg, services.log, parser.log and log4perl.properties.
There is a little extra functionality going on behind the scenes: If the configuration file moby-services.cfg does exist when you start the installation script, its values are used instead of default ones. It may be useful in cases when you plan to put all Perl Moses directories somewhere else (typically and for example, if your Web Server does not support symbolic links that can point to the current directories). It such case, edit your moby-services.cfg, put there new locations, and run install.pl again (run it from its new place - otherwise the pmoses_home will be still the old one).
#-----------------------------------------------------------------
# MOSES::MOBY::Data::GenericSequence
# Generated: 30-Jul-2006 14:55:09 BST
# Contact: Martin Senger <martin.senger@gmail.com> or
# Edward Kawas <edward.kawas@gmail.com>
#-----------------------------------------------------------------
package MOSES::MOBY::Data::GenericSequence;
no strict;
use vars qw( @ISA );
@ISA = qw( MOSES::MOBY::Data::VirtualSequence );
use strict;
use MOSES::MOBY::Data::Object;
#-----------------------------------------------------------------
# accessible attributes
#-----------------------------------------------------------------
{
my %_allowed =
(
'SequenceString' => {type => 'MOSES::MOBY::Data::String'},
);
sub _accessible {
my ($self, $attr) = @_;
exists $_allowed{$attr} or $self->SUPER::_accessible ($attr);
}
sub _attr_prop {
my ($self, $attr_name, $prop_name) = @_;
my $attr = $_allowed {$attr_name};
return ref ($attr) ? $attr->{$prop_name} : $attr if $attr;
return $self->SUPER::_attr_prop ($attr_name, $prop_name);
}
}
1;
__END__
=head1 NAME
...
The BioMoby data type objects are generated either on-the-fly
(more about it in a moment), or by using the
generate-datatypes.pl script.
The service base takes care about:
You can see its code by running (for example):
../scripts/generate-services.pl -sb samples.jmoby.net MabuhayAgain, the services bases can be generated and loaded on-the-fly, or pre-generated in the files.
Well, it is not that empty, after all.
First, because it inherits from its base, it already knows how to do all the features listed in the paragraph above:
#-----------------------------------------------------------------
# Service name: Mabuhay
# Authority: samples.jmoby.net
# Created: 29-Jul-2006 23:43:54 BST
# Contact: martin.senger@gmail.com
# Description: How to say "Hello" in many languages. Heavily based
# on a web resource "Greetings in more than 800 languages",
# maintained at http://www.elite.net/~runner/jennifers/hello.htm
# by Jennifer Runner.
#-----------------------------------------------------------------
package Service::Mabuhay;
use FindBin qw( $Bin );
use lib $Bin;
#-----------------------------------------------------------------
# This is a mandatory section - but you can still choose one of
# the two options (keep one and commented out the other):
#-----------------------------------------------------------------
use MOSES::MOBY::Base;
# --- (1) this option loads dynamically everything
BEGIN {
use MOSES::MOBY::Generators::GenServices;
new MOSES::MOBY::Generators::GenServices->load
(authority => 'samples.jmoby.net',
service_names => ['Mabuhay']);
}
# --- (2) this option uses pre-generated module
# You can generate the module by calling a script:
# cd jMoby/src/Perl
# ../scripts/generate-services.pl -b samples.jmoby.net Mabuhay
# then comment out the whole option above, and uncomment
# the following line (and make sure that Perl can find it):
#use net::jmoby::samples::MabuhayBase;
# (this to stay here with any of the options above)
use vars qw( @ISA );
@ISA = qw( net::jmoby::samples::MabuhayBase );
use MOSES::MOBY::Package;
use MOSES::MOBY::ServiceException;
use strict;
Second, it has the code that reads the input, using methods
specific for this service. It does not do anything with the input, but
the code shows you what methods you can use and how:
# read input data (eval to protect against missing data)
my $language = eval { $request->language };
my $format = eval { $language->format->value };
my $dotall_mode = eval { $language->dotall_mode->value };
my $regex = eval { $language->regex->value };
my $literal_mode = eval { $language->literal_mode->value };
my $multiline_mode = eval { $language->multiline_mode->value };
my $case_insensitive = eval { $language->case_insensitive->value };
my $comments = eval { $language->comments->value };
And finally, it produces a fake output (not related to the
input at all). Which is good because you can call the service
immediately, without writing a single line of code, and because you
see what methods can be used to create the real output:
# EDIT: PUT REAL VALUES INTO THE RESPONSE
# fill the response
foreach my $elem (0..2) {
my $hello = new MOSES::MOBY::Data::simple_key_value_pair
(
value => "this is a 'value $elem'", # TO BE EDITED
key => "this is a 'key $elem'", # TO BE EDITED
);
$response->add_hello ($hello);
}
The service implementations are definitely not generated
on-the-fly. They must be pre-generated into a file (because you
have to edit them, haven't you?). Again, the
generate-services.pl scripts will do it. More in scripts.
$DISPATCH_TABLE = {
'http://biomoby.org/#HelloBiomobyWorld' => 'Service::HelloBiomobyWorld',
'http://biomoby.org/#TextExtract' => 'Service::TextExtract',
'http://biomoby.org/#getRandomImage' => 'Service::getRandomImage',
'http://biomoby.org/#Mabuhay' => 'Service::Mabuhay',
'http://biomoby.org/#getRandomImage2' => 'Service::getRandomImage2'
};
The dispatch table is also not generated on-the-fly. It
is updated every time a service implementation is generated. Again,
the generate-services.pl scripts will do it. More in scripts.
How all these pieces fit together? Here we go:
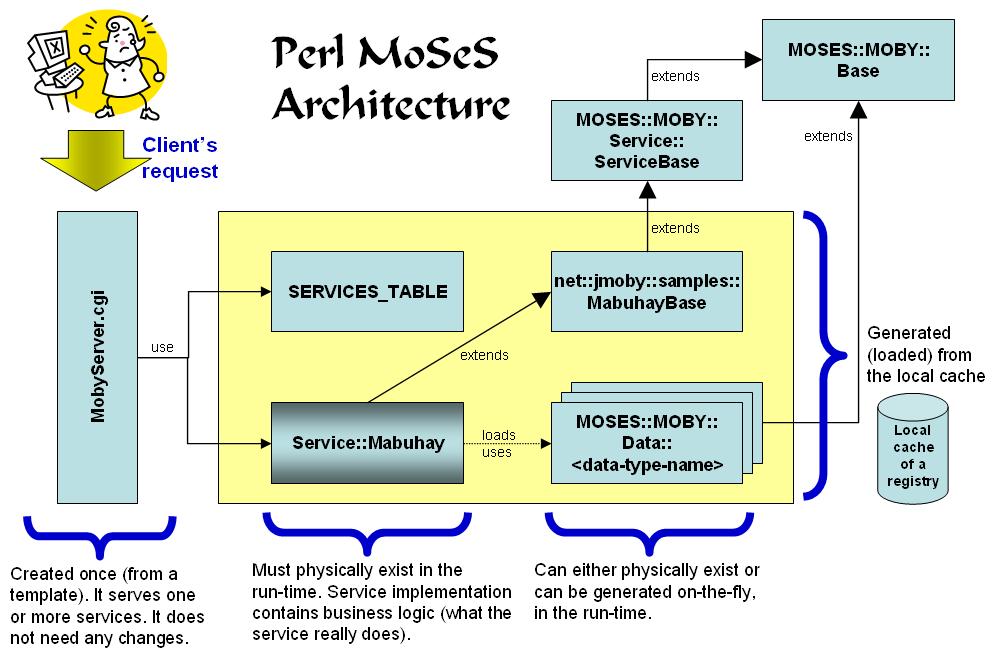
They share some basic features:
../scripts/<script-name>
perl -w ../scripts/<script-name>
Here they are in the alphabetic order:
Perl-MoSeS VERSION: 0.8
Configuration
-------------
Default configuration file: moby-services.cfg
Environment variable BIOMOBY_CFG_DIR is not set
Successfully read configuration files:
moby-services.cfg
All configuration parameters:
Mabuhay.resource.file => /home/senger/moby-live/Java/src/scripts/../../src/samples-resources/mabuhay.file
cachedir => /home/senger/moby-live/Java/src/scripts/../../myCache
default.cachedir => /home/senger/moby-live/Java/src/scripts/../../myCache
default.registry => default
generators.impl.outdir => /home/senger/moby-live/Java/src/scripts/../Perl/services
generators.impl.package.prefix => Service
generators.impl.services.table => SERVICES_TABLE
generators.outdir => /home/senger/moby-live/Java/src/scripts/../Perl/generated
log.level => debug
registry => default
All imported names (equivalent to parameters above):
$MOBYCFG::CACHEDIR
$MOBYCFG::DEFAULT_CACHEDIR
$MOBYCFG::DEFAULT_REGISTRY
$MOBYCFG::GENERATORS_IMPL_OUTDIR
$MOBYCFG::GENERATORS_IMPL_PACKAGE_PREFIX
$MOBYCFG::GENERATORS_IMPL_SERVICES_TABLE
$MOBYCFG::GENERATORS_OUTDIR
$MOBYCFG::LOG_CONFIG
$MOBYCFG::LOG_FILE
$MOBYCFG::LOG_LEVEL
$MOBYCFG::LOG_PATTERN
$MOBYCFG::MABUHAY_RESOURCE_FILE
$MOBYCFG::REGISTRY
$MOBYCFG::XML_PARSER
XML parser to be used: XML::LibXML::SAX
Logging
-------
Logger name (use it in the configuration file): services
Available appenders (log destinations):
Screen: stderr
Logging level FATAL: true
Logging level ERROR: true
Logging level WARN: true
Logging level INFO: true
Logging level DEBUG: true
Testing log messages (some may go only to a logfile):
2006/07/30 22:44:22 (295) FATAL> [[undef]] config-status.pl:117 - Missing Dunkin' Donuts
2006/07/30 22:44:22 (296) ERROR> [[undef]] config-status.pl:118 - ...and we are out of coffee!
This will generate all data types (it does not take that long: 300 data types just about 2.4 seconds on my laptop):
../scripts/generate-datatypes.plYou may see the progress on your screen if your logging is in debug level, and directed to the screen (more about it in logging).
You may generate also only named data types, of course. In which case, the script still asks the generator to generate also related data types (those representing the members of generated data types). It seems a reasonable assumption. For example, for:
../scripts/generate-datatypes.pl -d DNASequenceWithGFFFeaturesthe script reports to a log file (note the -d option to log in debug mode):
2006/07/30 23:00:33 (492) INFO> [[undef]] GenTypes.pm:125 - Data types will be generated into:
'/home/senger/moby-live/Java/src/scripts/../Perl/generated'
2006/07/30 23:00:33 (493) DEBUG> [[undef]] GenTypes.pm:149 - MOSES::MOBY::Data::BasicGFFSequenceFeature will be generated
2006/07/30 23:00:33 (665) DEBUG> [[undef]] GenTypes.pm:149 - MOSES::MOBY::Data::DNASequence will be generated
2006/07/30 23:00:33 (669) DEBUG> [[undef]] GenTypes.pm:149 - MOSES::MOBY::Data::DNASequenceWithGFFFeatures will be generated
2006/07/30 23:00:33 (673) DEBUG> [[undef]] GenTypes.pm:149 - MOSES::MOBY::Data::GenericSequence will be generated
2006/07/30 23:00:33 (676) DEBUG> [[undef]] GenTypes.pm:149 - MOSES::MOBY::Data::NucleotideSequence will be generated
2006/07/30 23:00:33 (680) DEBUG> [[undef]] GenTypes.pm:149 - MOSES::MOBY::Data::VirtualSequence will be generated
2006/07/30 23:00:33 (684) DEBUG> [[undef]] GenTypes.pm:149 - MOSES::MOBY::Data::multi_key_value_pair will be generated
An obvious question is "where are the data types generated to"? You can always find after generation in the log file - the message has the INFO level which means it is almost always logged. But, if you want to know in advance here are the rules:
You can use option -s to get the generated result directly on the screen (in that case no file is created).
The BioMoby primitive types (String, Integer, Float, Boolean and DateTime) are never generated. They were created manually.
For test-oriented geeks, here is how to check that the generated data types are syntactically correct (using Unix and bash commands):
senger@sherekhan:~/jMoby/src/Perl$ ../scripts/generate-datatypes.pl Generating all data types. Done. senger@sherekhan:~/jMoby/src/Perl$ for n in generated/MOSES/MOBY/Data/*.pm ; do perl -c $n ; done generated/MOSES/MOBY/Data/ABI_Encoded.pm syntax OK generated/MOSES/MOBY/Data/Ace_Text.pm syntax OK generated/MOSES/MOBY/Data/Alignment.pm syntax OK ... generated/MOSES/MOBY/Data/WU_BLAST_Text.pm syntax OK generated/MOSES/MOBY/Data/xdom_flatfile.pm syntax OK generated/MOSES/MOBY/Data/zPDB.pm syntax OK senger@sherekhan:~/jMoby/src/Perl$
Usually, you generate code for one or only several services. And because each service belongs to an authority you need to tell both:
../scripts/generate-services.pl samples.jmoby.net MabuhayIf you specify only an authority the code for all services from this authority will be generated:
../scripts/generate-services.pl samples.jmoby.netWithout any options (as shown above), it will generate service implementation classes, and it updates the dispatch table. However, it does not overwrite already existing service implementation - that would be dangerous because you may have already edited it and added there the real business logic:
Generating services from samples.jmoby.net:
Implementation '/home/senger/moby-live/Java/src/scripts/../Perl/services/Service/TextExtract.pm' already exists.
It will *not* be re-generated. Safety reasons.
Implementation '/home/senger/moby-live/Java/src/scripts/../Perl/services/Service/getRandomImage.pm' already exists.
It will *not* be re-generated. Safety reasons.
Implementation '/home/senger/moby-live/Java/src/scripts/../Perl/services/Service/HelloBiomobyWorld.pm' already exists.
It will *not* be re-generated. Safety reasons.
Implementation '/home/senger/moby-live/Java/src/scripts/../Perl/services/Service/Mabuhay.pm' already exists.
It will *not* be re-generated. Safety reasons.
Done.
[ There is an option to repress this cautious behaviour - look
into the script itself.] There are several configuration options to influence the result:
As with generated data types, here also you can use option -s to get the generated result directly on the screen (in that case no file is created).
For testing (and for fun) you can generate all services from all authorities (this time it is not that fast as data types, it takes almost 17 seconds - but who cares?):
../scripts/generate-services.pl -SaIn order to test syntax of all services, don't try the same trick as with data types, but look for the universal-testing.pl script.
../scripts/known-registries.plIn the time of writing this documentation, the response was (note that one of the registries is labeled as the "default" one):
IRRI, MIPS, default, iCAPTURE, testing
$Registries = {
'testing' => {
'namespace' => 'http://mobycentral.cbr.nrc.ca:8080/MOBY/Central',
'public' => 'yes',
'name' => 'Testing BioMoby registry',
'contact' => 'Edward Kawas (edward.kawas@gmail.com)',
'endpoint' => 'http://mobycentral.cbr.nrc.ca:8080/cgi-bin/MOBY05/mobycentral.pl'
},
'IRRI' => {
'namespace' => 'http://cropwiki.irri.org/MOBY/Central',
'text' => 'The MOBY registry at the International Rice Research
Institute (IRRI) is intended mostly for Generation Challenge Program
(GCP) developers. It allows the registration of experimental moby
entities within GCP.',
'public' => 'yes',
'name' => 'IRRI, Philippines',
'contact' => 'Mylah Rystie Anacleto (m.anacleto@cgiar.org)',
'endpoint' => 'http://cropwiki.irri.org/cgi-bin/MOBY-Central.pl'
},
'iCAPTURE' => {
'namespace' => 'http://mobycentral.icapture.ubc.ca/MOBY/Central',
'text' => 'A curated public registry hosted at the iCAPTURE Centre, Vancouver',
'public' => 'yes',
'name' => 'iCAPTURE Centre, Vancouver',
'contact' => 'Edward Kawas (edward.kawas@gmail.com)',
'endpoint' => 'http://mobycentral.icapture.ubc.ca/cgi-bin/MOBY05/mobycentral.pl'
},
'default' => $Registries->{'iCAPTURE'},
'MIPS' => {
'namespace' => 'http://mips.gsf.de/MOBY/Central',
'name' => 'MIPS, Germany',
'contact' => 'Dirk Haase (d.haase@gsf.de)',
'endpoint' => 'http://mips.gsf.de/cgi-bin/proj/planet/moby/MOBY-Central.pl'
}
};
This script does not have any options (nor the help).
Show a data type:
../scripts/local-cache.pl -t DNASequence
-> MOSES::MOBY::Def::DataType=HASH(0x86026b8)
'authority' => 'www.illuminae.com'
'children' => ARRAY(0x86028b0)
empty array
'description' => 'Lightweight representation a DNA sequence'
'email' => 'markw@illuminae.com'
'lsid' => 'urn:lsid:biomoby.org:objectclass:DNASequence:2001-09-21T16-00-00Z'
'module_name' => 'MOSES::MOBY::Data::DNASequence'
'module_parent' => 'MOSES::MOBY::Data::NucleotideSequence'
'name' => 'DNASequence'
'parent' => 'NucleotideSequence'
As you see this did not show all children
(members). If you want it, use the -c option instead:
../scripts/local-cache.pl -c DNASequence
All children of 'DNASequence': -> MOSES::MOBY::Def::Relationship=HASH(0x860e608) 'datatype' => 'String' 'memberName' => 'SequenceString' 'module_datatype' => 'MOSES::MOBY::Data::String' 'original_memberName' => 'SequenceString' 'relationship' => 'HASA' -> MOSES::MOBY::Def::Relationship=HASH(0x863a3bc) 'datatype' => 'Integer' 'memberName' => 'Length' 'module_datatype' => 'MOSES::MOBY::Data::Integer' 'original_memberName' => 'Length' 'relationship' => 'HASA'Option -r shows all related (used) data types:
../scripts/local-cache.pl -r DNASequence
DNASequence GenericSequence Integer NucleotideSequence Object String VirtualSequenceOptions -s shows service definitions.
Both data types and services can be shown in XML, using the -x option. The XML is actually identical with the registration request for the given entity. This is just a side-effect - but perhaps it can be useful:
../scripts/local-cache.pl -xs samples.jmoby.net getRandomImage
<moby:registerService xmlns:moby="http://www.biomoby.org/moby">
<moby:Category xmlns:moby="http://www.biomoby.org/moby">moby</moby:Category>
<moby:serviceName xmlns:moby="http://www.biomoby.org/moby">getRandomImage</moby:serviceName>
<moby:serviceType xmlns:moby="http://www.biomoby.org/moby">Retrieval</moby:serviceType>
<moby:contactEmail xmlns:moby="http://www.biomoby.org/moby">martin.senger@gmail.com</moby:contactEmail>
<moby:authURI xmlns:moby="http://www.biomoby.org/moby">samples.jmoby.net</moby:authURI>
<moby:Description xmlns:moby="http://www.biomoby.org/moby"><![CDATA[It brings back a random image. But a user can influence the choice of the returned image by requesting an image by sending a particular number (unknown numbers are ignored, and a random image is returned).
]]></moby:Description>
<moby:signatureURL xmlns:moby="http://www.biomoby.org/moby"/>
<moby:URL xmlns:moby="http://www.biomoby.org/moby">http://mobycentral.icapture.ubc.ca:8090/axis/services/getRandomImage</moby:URL>
<moby:authoritativeService xmlns:moby="http://www.biomoby.org/moby">1</moby:authoritativeService>
<moby:Input xmlns:moby="http://www.biomoby.org/moby">
<moby:Simple xmlns:moby="http://www.biomoby.org/moby" moby:articleName="imageNumber">
<moby:objectType xmlns:moby="http://www.biomoby.org/moby">Integer</moby:objectType>
</moby:Simple>
</moby:Input>
<moby:secondaryArticles xmlns:moby="http://www.biomoby.org/moby"/>
<moby:Output xmlns:moby="http://www.biomoby.org/moby">
<moby:Simple xmlns:moby="http://www.biomoby.org/moby" moby:articleName="image">
<moby:objectType xmlns:moby="http://www.biomoby.org/moby">text-base64</moby:objectType>
</moby:Simple>
</moby:Output>
</moby:registerService>
Option -l is for getting list of all names: of data types
(when used together with the -t option), or of services (with
-s option). You can also see how many entities are currently cached in your local cache. It shows what is the current registry you are using (it takes it from the configuration option registry), and the numbers for all cached registries. Use option -i (as for information):
../scripts/local-cache.pl -i
Currently used registry: default (it can be changed in moby-services.cfg) contact : Edward Kawas (edward.kawas@gmail.com) endpoint : http://mobycentral.icapture.ubc.ca/cgi-bin/MOBY05/mobycentral.pl name : iCAPTURE Centre, Vancouver namespace : http://mobycentral.icapture.ubc.ca/MOBY/Central public : yes text : A curated public registry hosted at the iCAPTURE Centre, Vancouver Statictics for all locally cached registries: Registry Data types Authorities Services IRRI 305 61 553 MIPS 54 9 165 default 307 57 451 iCAPTURE 307 57 451
../scripts/testing-parser.pl ~/jMoby/data/parser-test-input2.xml ../scripts/testing-parser.pl -r ~/jMoby/data/parser-test-input2.xmlAn interesting is the -b parameter. It has the form:
-b <input-name>:<known-type>and it indicates a backup data type that is used when an unknown XML top-level tag is encountered. This is not usually needed at all - only when your data type definitions, the generated data types, are not up-to-date. If such situation occurs the input data with article name <input-name> will use the <known-type>.
It calls a BioMoby service in one of the two modes (actually the two modes are completely separated to the point that this script could be two scripts):
In both modes, the script can send an input XML file to the service - but if the file is not given, an empty input is created and sent to the service. Which is not particularly useful, but still it can help with some preliminary testing.
When calling the service locally, you may use the following options/parameters:
../scripts/testing-service.pl -d Service::HelloBiomobyWorldThe output of this call was already shown in this documentation. Therefore, just look what debug messages were logged (notice the -d option used):
2006/07/31 02:19:37 (561) INFO> [23856] HelloBiomobyWorldBase.pm:92 - *** REQUEST START ***
2006/07/31 02:19:37 (562) DEBUG> [23856] HelloBiomobyWorldBase.pm:98 - Input raw data:
<?xml version="1.0" encoding="UTF-8"?>
<moby:MOBY xmlns:moby="http://www.biomoby.org/moby">
<moby:mobyContent>
<moby:mobyData moby:queryID="job_0"/>
</moby:mobyContent>
</moby:MOBY>
2006/07/31 02:19:37 (687) INFO> [23856] HelloBiomobyWorldBase.pm:160 - *** RESPONSE READY ***
The full mode has the following options/parameters:
../scripts/testing-service.pl \
-e http://localhost/cgi-bin/MobyServer.cgi HelloBiomobyWorld
There are also few other behavioral differences between these two modes: If an input parsing error occurs (e.g. when an input has an unknown article name), it is reported directly to the standard error in the testing mode, but in a real mode it is properly included in the response as an exception. Or (and only if the logging is set to record debug messages), in testing mode the full input raw (not yet parsed) are logged, whereas in the real mode only the first 1000 characters are logged.
It can be called also for a subset of services, usually for services from an authority:
../scripts/universal-testing.pl bioinfo.icapture.ubc.ca
Services will be generated into: /tmp/generated-services Services will be in package: Testing::For some services, it produces warnings - but they are just the consequence of the way how the example methods (in service implementation) were generated. They do not mean anything wrong. There may be, however, some other warnings, that are consequence of the fact that a service is registered with empty article names (which should not be, but there are still such services in some registries).Services outputs will be saved in: /tmp/generated-outputs ---------------------------------- Service: bioinfo.icapture.ubc.ca getKeggPathwayAsGif Service: bioinfo.icapture.ubc.ca getKeggPathwaysByKeggID Service: bioinfo.icapture.ubc.ca ExplodeOutCrossReferences Service: bioinfo.icapture.ubc.ca getUniprotIdentifierByGeneName Service: bioinfo.icapture.ubc.ca convertIdentifier2KeggID Service: bioinfo.icapture.ubc.ca getGoTerm Service: bioinfo.icapture.ubc.ca MOBYSHoundGetGenBankGFF "my" variable $id masks earlier declaration in same scope at /tmp/generated-services/Testing/MOBYSHoundGetGenBankGFF.pm line 58. Service: bioinfo.icapture.ubc.ca getKeggIdsByKeggPathway Service: bioinfo.icapture.ubc.ca MOBYSHoundGetGenBankVirtSequence Service: bioinfo.icapture.ubc.ca getJpegFromAnnotatedImage Service: bioinfo.icapture.ubc.ca FASTA2HighestGenericSequenceObject Service: bioinfo.icapture.ubc.ca Parse_GeneMarkHMM_HTML Service: bioinfo.icapture.ubc.ca GeneMarkHMM_Arabidopsis Service: bioinfo.icapture.ubc.ca MOBYSHoundFindAccEMBL2gi Service: bioinfo.icapture.ubc.ca renderGFF Service: bioinfo.icapture.ubc.ca MOBYSHoundGetGenBankFasta Service: bioinfo.icapture.ubc.ca RetrieveGOFromKeywords Service: bioinfo.icapture.ubc.ca getGoTermAssociations Service: bioinfo.icapture.ubc.ca MOBYSHoundGetGenBankWhateverSequence Service: bioinfo.icapture.ubc.ca getTaxChildNodes Service: bioinfo.icapture.ubc.ca getTaxNameFromTaxID Service: bioinfo.icapture.ubc.ca getTaxParent Service: bioinfo.icapture.ubc.ca MOBYSHoundGetGenBankff Service: bioinfo.icapture.ubc.ca getSHoundProteinsFromTaxID Service: bioinfo.icapture.ubc.ca getSHoundDNAFromTaxID Service: bioinfo.icapture.ubc.ca getSHoundDNAFromOrganism Service: bioinfo.icapture.ubc.ca getSHoundProteinFromOrganism Service: bioinfo.icapture.ubc.ca getSHoundNeighboursFromGi Service: bioinfo.icapture.ubc.ca getSHound3DNeighboursFromGi Service: bioinfo.icapture.ubc.ca getSHoundGODBGetParentOf Service: bioinfo.icapture.ubc.ca getSHoundGODBGetChildrenOf Service: bioinfo.icapture.ubc.ca GenericSequence2FASTA
It has one interesting feature that can be useful outside of pure testing: It keeps all outputs from all services in a (temporary) directory. These outputs may have fake values but they are not empty, and they represent correct output data types. For example, a service tropgenedb.cirad.fr created this (quite complex) output:
<moby:MOBY xmlns:moby="http://www.biomoby.org/moby">
<moby:mobyContent moby:authority="tropgenedb.cirad.fr">
<moby:serviceNotes>
<moby:Notes>Response created at Sun Jul 30 23:23:08 2006 (GMT),
by the service 'getTropgeneMapInformation'.</moby:Notes>
</moby:serviceNotes>
<moby:mobyData moby:queryID="job_0">
<moby:Collection moby:articleName="map">
<moby:Simple>
<moby:GCP_Map moby:id="" moby:namespace="">
<moby:Float moby:id="" moby:namespace="" moby:articleName="length">0.42</moby:Float>
<moby:GCP_Locus moby:id="" moby:namespace="" moby:articleName="locus">
<moby:GCP_MapPosition moby:id="" moby:namespace="" moby:articleName="start_stop">
<moby:Float moby:id="" moby:namespace="" moby:articleName="position">0.42</moby:Float>
</moby:GCP_MapPosition>
<moby:GCP_Allele moby:id="" moby:namespace="" moby:articleName="allele"/>
</moby:GCP_Locus>
</moby:GCP_Map>
</moby:Simple>
<moby:Simple>
<moby:GCP_Map moby:id="" moby:namespace="">
<moby:Float moby:id="" moby:namespace="" moby:articleName="length">0.42</moby:Float>
<moby:GCP_Locus moby:id="" moby:namespace="" moby:articleName="locus">
<moby:GCP_MapPosition moby:id="" moby:namespace="" moby:articleName="start_stop">
<moby:Float moby:id="" moby:namespace="" moby:articleName="position">0.42</moby:Float>
</moby:GCP_MapPosition>
<moby:GCP_Allele moby:id="" moby:namespace="" moby:articleName="allele"/>
</moby:GCP_Locus>
</moby:GCP_Map>
</moby:Simple>
<moby:Simple>
<moby:GCP_Map moby:id="" moby:namespace="">
<moby:Float moby:id="" moby:namespace="" moby:articleName="length">0.42</moby:Float>
<moby:GCP_Locus moby:id="" moby:namespace="" moby:articleName="locus">
<moby:GCP_MapPosition moby:id="" moby:namespace="" moby:articleName="start_stop">
<moby:Float moby:id="" moby:namespace="" moby:articleName="position">0.42</moby:Float>
</moby:GCP_MapPosition>
<moby:GCP_Allele moby:id="" moby:namespace="" moby:articleName="allele"/>
</moby:GCP_Locus>
</moby:GCP_Map>
</moby:Simple>
</moby:Collection>
</moby:mobyData>
</moby:mobyContent>
</moby:MOBY>
Perl Moses stores configuration in a file named moby-services.cfg. The file name is hard-coded (and cannot be changed without changing the MOSES::MOBY::Config module), but its location can be set using an environment variable BIOMOBY_CFG_DIR. Perl Moses looks for its configuration place in the following places, in this order:
Therefore, the best place is to keep the configuration file together with the Perl Moses code, in the directory moby-live/Java/src/Perl - where the installation script puts it anyway.
The Perl Moses internally uses Config::Simple CPAN module, but wraps it into its own MOSES::MOBY::Config. This allows expansion later, or even changing the underlying configuration system. The Config::Simple is simple (thus the name, and thus we selected it) but has few drawbacks that may be worth to work on later.
The file format is as defined by the Config::Simple. It can be actually of several formats. The most common is the one distributed in the moby-services.cfg.template. This is an example of a configuration file:
cachedir = /home/senger/moby-live/Java/src/scripts/../../myCache
registry = default
[generators]
outdir = /home/senger/moby-live/Java/src/scripts/../Perl/generated
impl.outdir = /home/senger/moby-live/Java/src/scripts/../Perl/services
impl.package.prefix = Service
impl.services.table = SERVICES_TABLE
#ignore.existing.types = true
[log]
config = /home/senger/moby-live/Java/src/scripts/../Perl/log4perl.properties
#file = /home/senger/moby-live/Java/src/scripts/../Perl/services.log
#level = info
#pattern = "%d (%r) %p> [%x] %F{1}:%L - %m%n"
[xml]
#parser = XML::LibXML::SAX
#parser = XML::LibXML::SAX::Parser
#parser = XML::SAX::PurePerl
[Mabuhay]
resource.file = /home/senger/moby-live/Java/src/scripts/../../src/samples-resources/mabuhay.file
The names of the configuration parameters are created by concatenating
the "section" name (the one in the square brackets) and the name
itself. For example, the XML parser is specified by the parameter
xml.parser. Parameters that are outside of any section
(e.g. cachedir) has just their name, or they can be referred
to as from the default section. For example, these two names
are equivalent: default.cachedir and cachedir. Blank lines are ignored, comments lines start with a hash (#), and boolean properties must have a value ('true' or 'false').
Obviously, important is to know what can be configured, and how. This document on various places already mentioned several configuration options. Here is their list (for more explanations about their purpose you may visit an appropriate section of this document):
The parameters just described are used by PerlMoses modules - but the configuration system is here also for your own services. You can invent any not-yet-taken name, and add your own parameter. In order not to clash with the future Perl Moses parameters, it is recommended to prefix your configuration properties with the service name. For example, the Mabuhay service needs to read a file with "hellos" in many languages, so it defines:
[Mabuhay] resource.file = /home/senger/moby-live/Java/src/scripts/../../src/samples-resources/mabuhay.file
How to use configuration in your service implementation?
All configuration parameters are imported to a Perl namespace MOBYCFG. The imported names are changed to all-uppercase and dots are replaces by underscores. You can see this change if you run the config-status.cfg:
$MOBYCFG::CACHEDIR $MOBYCFG::DEFAULT_CACHEDIR $MOBYCFG::DEFAULT_REGISTRY $MOBYCFG::GENERATORS_IMPL_OUTDIR $MOBYCFG::GENERATORS_IMPL_PACKAGE_PREFIX $MOBYCFG::GENERATORS_IMPL_SERVICES_TABLE $MOBYCFG::GENERATORS_OUTDIR $MOBYCFG::LOG_CONFIG $MOBYCFG::LOG_FILE $MOBYCFG::LOG_LEVEL $MOBYCFG::LOG_PATTERN $MOBYCFG::MABUHAY_RESOURCE_FILE $MOBYCFG::REGISTRY $MOBYCFG::XML_PARSERIn your program, you can use the imported names. For example, here is how the Mabuhay service opens its resource file:
open HELLO, $MOBYCFG::MABUHAY_RESOURCE_FILE
or $self->throw ('Mabuhay resource file not found.');
You can also change or add parameters during the run-time. For
example, the script universal-testing.pl needs to overwrite
existing parameters because it wants to create everything in a
separate space, in a temporary directory, and within the 'Testing'
package. Because the generators read from the configuration files, it
is necessary to change it there:
my $outdir = File::Spec->catfile ($tmpdir, 'generated-services');
MOSES::MOBY::Config->param ('generators.impl.outdir', $outdir);
MOSES::MOBY::Config->param ('generators.impl.package.prefix', 'Testing');
unshift (@INC, $MOBYCFG::GENERATORS_IMPL_OUTDIR);
my $generator = new MOSES::MOBY::Generators::GenServices;
More about how to communicate pragmatically with the configuration can
be (hopefully) find in the Perl Modules
Documentation. How does it work in Perl Moses?
The logging is available from the moment when Perl Moses knows about the MOSES::MOBY::Base module. All generated service implementations inherit from this class, so all of them have immediate access to the logging system. By default, the MOSES::MOBY::Base creates a logger in a variable $LOG. Which means that in your service implementation you can log events in five different log levels:
$LOG->debug ("Deep in my mind, I have an idea...");
$LOG->info ("What a nice day by a keyboard.");
$LOG->warn ("However, the level of sugar is decreasing!");
$LOG->error ("Missing Dunkin' Donuts");
$LOG->fatal ('...and we are out of coffee!');
The logger name is "services". (The name is used in the logging
configuration file - see below). You can create your own logger. Which may be good if you wish to have, for example, a different logging level for a particular service, or for a part of it (an example of such situation is in MOSES::MOBY::Parser.pm where the parser creates its own $PLOG logger). Here is what you need to do:
use Log::Log4perl qw(get_logger :levels);
my $mylog = get_logger ('my_log_name');
Then use the name "my_log_name" in the configuration to set its own
properties. Which brings also us to the logging configuration. The logging configuration can be done in three ways:
If Perl Moses cannot find a log4perl.properties file, and if there are no logging options in moby-services.cfg, it assumes some defaults (check them in MOSES::MOBY::Base, in its BEGIN section, if you need-to-know).
The better way is to use log4perl.properties file. The file name can be actually different - it is specified by an option log.config in the moby-services.cfg configuration file. This is what PerlMoses installation creates there (of course, using your own path):
[log] config = /home/senger/moby-live/Java/src/scripts/../Perl/log4perl.propertiesThe log4perl.properties is created (in the installation time) from the log4perl.properties.template, by putting there your specific paths to log files. The log4perl (or log4j) documentation explains all details - here is just a brief example what is in the file and what it means:
log4perl.logger.services = INFO, Screen, Log
log4perl.appender.Screen = Log::Log4perl::Appender::Screen
log4perl.appender.Screen.stderr = 1
log4perl.appender.Screen.Threshold = FATAL
log4perl.appender.Screen.layout = Log::Log4perl::Layout::PatternLayout
log4perl.appender.Screen.layout.ConversionPattern = %d (%r) %p> [%x] %F{1}:%L - %m%n
log4perl.appender.Log = Log::Log4perl::Appender::File
log4perl.appender.Log.filename = /home/senger/moby-live/Java/src/scripts/../Perl/services.log
log4perl.appender.Log.mode = append
log4perl.appender.Log.layout = Log::Log4perl::Layout::PatternLayout
log4perl.appender.Log.layout.ConversionPattern = %d (%r) %p> [%x] %F{1}:%L - %m%n
It says: Log only INFO (and above) levels (so no DEBUG messages are
logged) on the screen (meaning on the STDERR) and to a file. But
because of the "screen appender" has defined a Threshold
FATAL - the screen (STDERR) will get only FATAL messages. There is no
threshold in the "file appender" so the file gets all the INFO, WARN,
ERROR and FATAL messages. In both cases the format of the messages is
defined by the "ConversionPattern". Note that printing to STDERR means that the message will go to the error.log file of your Web Server.
To change the log level to DEBUG, replace INFo by DEBUG in the first line.
The message format (unless you change the Perl Moses default way) means:
%d (%r ) %p > [%x ] %F{1} :%L - %m %n
2006/07/31 11:38:07 (504) FATAL> [26849] HelloBiomobyWorld.pm:63 - Go away!
1 2 3 4 5 6 7 8
Where:
The last option how to specify logging properties is to set few configuration options in the moby-service.cfg file. It was already mentioned that there is an option log.config that points to a full log property file. If this option exists, no other logging configuration options are considered. But if you comment it out, you can set the basics in the following options:
[log]
#config = /home/senger/moby-live/Java/src/scripts/../Perl/log4perl.properties
file = /home/senger/moby-live/Java/src/scripts/../Perl/services.log
level = info
pattern = "%d (%r) %p> [%x] %F{1}:%L - %m%n"
Where log.file defines a log file, log.level
specifies what events will be logged (the one mentioned here and
above), and the log.pattern creates the format of the log
events. This is meant for a fast change in the logging system (perhaps during the testing phase).
There are definitely more features in the Log4perl system to be explored:
For example, in the mod_perl mode it would be interesting to use the "Automatic reloading of changed configuration files". In this mode, Log::Log4perl will examine the configuration file every defined number of seconds for changes via the file's last modification time-stamp. If the file has been updated, it will be reloaded and replace the current logging configuration.
Or, one can explore additional log appenders (you will need to install additional Perl modules for that) allowing, for example, to rotate automatically log files when they reach a given size. See the Log4perl documentation for details.
By contrast to the deployment of the Java-based services, Perl services are invoked by a cgi-bin script directly from a Web Server - there is no other container, such as Tomcat in the Java world. Which makes the life slightly easier. Well, only slightly, because soon you will start to think about using mod_perl module, and it may make things complicated.
use strict; use SOAP::Transport::HTTP; # --- established in the install.pl time use lib '/home/senger/moby-live/Java/src/scripts/../Perl'; use lib '/home/senger/moby-live/Java/src/scripts/../Perl/generated'; use lib '/home/senger/moby-live/Java/src/scripts/../Perl/services'; # --- list of all services served by this script use vars qw ( $DISPATCH_TABLE ); require "SERVICES_TABLE"; # --- accept request and call wanted service my $x = new SOAP::Transport::HTTP::CGI; $x->dispatch_with ($DISPATCH_TABLE); $x->handle;
These three things (a Web Server knowing about your cgi-bin script, a cgi-bin script knowing about Perl Moses code, and a dispatch table knowing what services to serve) are all you need to have your service deployed.
How to write a service implementation
First of all, you need to have a service implementation, at least its starting (empty) phase. Generate it, using the generated-services.pl script. Depending on how you generate it (without any option, or using an -S option) generator enables one of the following options (not that it matters to your business logic code):
#-----------------------------------------------------------------
# This is a mandatory section - but you can still choose one of
# the two options (keep one and commented out the other):
#-----------------------------------------------------------------
use MOSES::MOBY::Base;
# --- (1) this option loads dynamically everything
BEGIN {
use MOSES::MOBY::Generators::GenServices;
new MOSES::MOBY::Generators::GenServices->load
(authority => 'samples.jmoby.net',
service_names => ['Mabuhay']);
}
# --- (2) this option uses pre-generated module
# You can generate the module by calling a script:
# cd jMoby/src/Perl
# ../scripts/generate-services.pl -b samples.jmoby.net Mabuhay
# then comment out the whole option above, and uncomment
# the following line (and make sure that Perl can find it):
#use net::jmoby::samples::MabuhayBase;
Secondly, you need to understand when and how your implementation code
is called: Every BioMoby request can have multiple queries (in the Moses world, called jobs). Your service implementation has to implement method process_it that is called for every individual job contained within every incoming request. The MOSES/MOBY/Service/ServiceBase has details about this method (what parameters it gets, how to deal with exceptions, etc.).
In the beginning of the generated process_it method is the code that tells you what methods are available for reading inputs, and at the end of the same method is the code showing how to fill the response. Feel free to remove the code, extend it, fill it, turn it upside-down, whatever. This is, after all, your implementation. And Perl Moses generator is clever enough not to overwrite the code once is generated. (It is not clever enough, however, to notice that it could be overwritten because you have not touched it yet.)
Perhaps the best way how to close this section is to show a full implementation of (so often mentioned) service Mabuhay (the code is also available in jMoby/src/Perl/samples):
sub process_it {
my ($self, $request, $response, $context) = @_;
# read (some) input data
# (use eval to protect against missing data)
my $language = eval { $request->language };
my $regex = eval { $language->regex->value };
my $ignore_cases = eval { $language->case_insensitive->value };
# set an exception if data are not complete
unless ($language and $regex) {
$response->record_error ( { code => INPUTS_INVALID,
msg => 'Input regular expression is missing.' } );
return;
}
# creating an answer (this is the "business logic" of this service)
my @result_hellos = ();
my @result_langs = ();
open HELLO, $MOBYCFG::MABUHAY_RESOURCE_FILE
or $self->throw ('Mabuhay resource file not found.');
while (<HELLO>) {
chomp;
my ($lang, $hello) = split (/\t+/, $_, 2);
if ( $ignore_cases ?
$lang =~ /$regex/i :
$lang =~ /$regex/ ) {
push (@result_hellos, $hello);
push (@result_langs, $lang);
}
}
close HELLO;
foreach my $idx (0 .. $#result_hellos) {
$response->add_hello (new MOSES::MOBY::Data::simple_key_value_pair
( key => $self->as_uni_string ($result_langs[$idx]),
value => $self->as_uni_string ($result_hellos[$idx])
));
}
}
When you go through the code above you notice how to do basic things
that almost every service has to do. Which are:
What was not pre-generated are the methods accessing ID and NAMESPACE. Their names are, not surprisingly, id and namespace. For example, the Mabuhay input is named language (as seen in the code above), so you can call:
$language->id; $language->namespace;The question is what to do if input (or anything else) is not complete or valid. This brings us to...
open HELLO, $MOBYCFG::MABUHAY_RESOURCE_FILE
or $self->throw ('Mabuhay resource file not found.');
This immediately stops the processing of the input request
(ignoring all remaining jobs if they are some still there), the text
of the error message is put into the response as an exception with the
code 600 ("INTERNAL_PROCESSING_ERROR"), the same message is logged as
an error, and the response is sent back to the client. Note, however, that the response may already contain some outputs from the previously processed jobs. If you do not like it, you can remove it (find them in the $context parameter).
Another, less drastic, option is to record an exception (and, usually, return):
$response->record_error ( { code => INPUTS_INVALID,
msg => 'Input regular expression is missing.' } );
This creates an exception in the response - you choose what
code to use -, and it does not prevent processing of the remaining (if
any) jobs. In addition to using an eval{} block to handle exceptions (as shown above), you can also use a try-catch-finally block structure if Error.pm has been installed in your system. See documentation of MOSES::MOBY::Base for details and examples.
Again here you can also set the ID and NAMESPACE. For example, the code above can be extended so the MOSES::MOBY::Data::simple_key_value_pair data type will have also an ID and NAMESPACE:
$response->add_hello (new MOSES::MOBY::Data::simple_key_value_pair
( key => $self->as_uni_string ($result_langs[$idx]),
value => $self->as_uni_string ($result_hellos[$idx]),
id => 'this is an ID',
namespace => 'this is a NAMESPACE'
));
# create a simple cross-reference
my $simple_xref = new MOSES::MOBY::Data::Xref
( id => 'At263644',
namespace => 'TIGR'
);
# create an advanced cross-reference
my $advanced_xref = new MOSES::MOBY::Data::Xref
( id => 'X112345',
namespace => 'EMBL',
service => 'getEMBLRecord',
authority => 'www.illuminae.com',
evidenceCode => 'IEA',
xrefType => 'transform'
);
# add them to the output object (which has an article name 'greeting')
$response->greeting->add_xrefs ($simple_xref);
$response->greeting->add_xrefs ($advanced_xref);
$context->serviceNotes ("This is my note...");
The Perl documentation is (as usual in Perl) part of the Perl code, embedded there. It is generated when needed. Therefore, if some (or all) links in this section are broken it means that nobody generated the underlying POD documentation yet. This may easily happen if you are browsing your own copy of the documentation as it comes from the CVS. In such case, please type first:
../scripts/generate-doc.pl
 Waiting for the first question...
Waiting for the first question...
And there are features (and known) bugs that should or could be implemented (or fixed). Here are those I am aware of (B = bug, N = not yet implemented, F = potential future feature):
I will try to keep up-to-date the list of the recent changes in the ChangeLog.
However, there would be no MoSeS without BioMoby - flowers go to Mark Wilkinson from the University of British Columbia. Also and of course, nothing could be done without enthusiastic support from the BioMoby community.
Martin Senger was developing the project in the frame of the Generation Challenge Programme, getting non-nonsense support from Richard Bruskiewich from the International Rice Research Institute in Philippines, and high motivation to work with Perl from Mathieu Rouard from INIBAP.