The generators generate source code in Java. But there is probably nothing significant precluding to generate also code in Perl - perhaps we will have in the future (if we want to).
All invocations shown below are meant to be used from a jMoby CVS local copy, using Java's Ant. General instructions about jMoby's Ant are in a separate document, but this document adds to it new Ant's targets.
jMoby supports caching that is not too clever at the moment, but still quite useful in many cases: It caches locally (in your file system, not in a database) data types definitions and service instance definitions if you specify a -cachedir option (in the command-line clients), or a registry.cache.dir property (when using Ant). If the cache does not exist yet it is created and filled. If it exists it is used. But it is "either or" - it does not have capability (yet) to find that some objects in the cache should be updated and some not. Therefore, if you want to get latest entities from the registry, remove the cache, or stop using the cache option or property.
Note that you can also fill the cache, remove the cache , or find how old your cached objects are using a specialized command-line client CacheRegistryClient. Just type:
Obviously, the best would be to used caching together with the newer option in the Biomoby API: access to resources "in-one-go" by fetching RDF documents. It will come...build/run/run-cache-client -help
The current caching produces contents of entities but not there lists. So every time you start a generator, it still needs a network access to get a list of names from a Biomoby registry. This is usually a short trip but necessary with the current implementation of caching. Yes. it is another thing that should (and easily could) be improved...
By default, it creates source code in directory generated/datatypes - and even though this can be changed (see below Ant property src.datatypes or a command-line option -outdir) usually there is no need to do it.
It always generates code into the package org.biomoby.shared.datatypes. Do not be confused: the contents of the same package can be stored in more than one place - and it is like that also with this package: the generated code is put into generated/datatypes and the existing (not-generated) code for objects representing Biomoby primitive types is in src/main. But you do not need to know this...
Generator generates one class per Biomoby data type - and additionally a mapping class org.biomoby.shared.datatypes.MapDataTypes that maps Biomoby names to Java classes. Usually, they are the same (except of the package name added to the Java classes names) but generator must protect itself against a non-Java compliant identifiers - so it changes, for example, Biomoby data type text-base64 to text_base64. Also the Biomoby primitive data types have slightly different names (String becomes MobyString and so on).
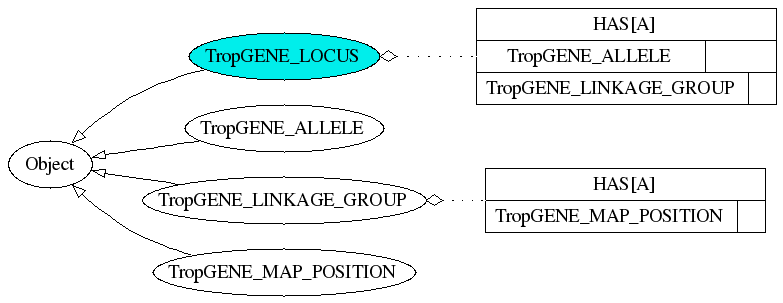
The generated source code is annotated (in the API comments, visible in the API documentation generated by javadoc) by information taken from the registry. It also shows (unless it is disabled - see options below) the full tree of the data type and of the participating Biomoby objects. The tree is click-able so you can navigate from one data type to the others. Here is an example of such generated API for a data type TropGENE_LOCUS:
And here is another one, with slightly more complex path to its root - a data type for DNASequenceWithGFFFeatures:

The same can be achieved by invoking Ant's specialized targets. More about them below. For now let just put the corresponding Ant properties in the parameter tables.build/run/run-generator <options>
The program takes the following options, specific for generating data types:
| Option/Parameter | Ant's property | Meaning |
|---|---|---|
| -dt | generate data types (a mandatory option) | |
| -filter <reg-expr> | moses.filter.dt | What data types to generate. Put here names of data types as regular expression - but usually you want to generate all of them. This is therefore an option mostly for debugging - but see a "Rubbish" example below. |
Here is a few typical examples:
Generate all data types with default values:
When I was testing the generator I found some unpleasant (meaning inconsistent with the Biomoby API) data types in a Biomoby registry. Their names started with "Rubbish" and they have duplicated article names - which would produce a non-compilable Java code. Here is how I filtered them out (note that the backslash in front of the exclamation mark is because of the shell interpreter, it is not part of the regular expression itself):build/run/run-generator -dt
The program also takes more generic options that are shared with generating service skeletons:build/run/run-generator -dt -filter '^(?\!Rubbish)'
| Option/Parameter | Ant's property | Meaning |
|---|---|---|
| -e <endpoint> | default.endpoint | A URL of a Biomoby registry where this generator will go to fetch information about generated entities. It has a default value so usually it is not needed. |
| -uri <namespace> | default.namespace | A namespace/URI of a Biomoby registry. Again its default value is usually fine. |
| -cachedir <directory> | registry.cache.dir | A local directory where are cached Biomoby object. Use this option even if you do not have a cache - and it will be created so the next time generators will run faster -see note on caching. |
| -outdir <directory> | src.datatypes or src.skeletons |
A directory where the results go to. Default is generated. |
| -q | moses.quiet | less verbose output (quiet) |
| -n | moses.nogener | do NOT generate anything, just show what WOULD be generated |
| -ng | moses.nographs | Do NOT include graphs (showing connections to other Biomoby entities) in the generated Java API. This makes generating slightly faster. |
| -dot <full-path> | dot.location | The graphs (unless disabled by an -ng option) are
created using an external program dot (from the Graphviz package). If
this program is not on your PATH, specify here where it is (including its name). If a generator cannot find it, it silently ignores it - but in such case it produces at least the .dot files that can be later used to create images from them. Both picture or dot files are stored in generated/datatypes/org/biomoby/shared/datatypes/doc-files. |
More examples:
Do not generate anything but shows what would be generated. It is good for testing your regular expression in the -filter option:
If you do not have the dot program on your path:build/run/run-generator -dt -n
build/run/run-generator -dt -dot /home/senger/software/bin/dot
Once the Java code for data types was generated it is time to compile it (and use it). For that there are new Ant's targets (just a reminder: if you are interested to see all Ant's targets available in current jMoby, see this graph). I have highlighted the names of the targets using bold font.
This does it all. Remember that setting a cache directory is very recommended (remember that you can always put all properties in your build.properties file instead of putting them on the command-line with the -D options):
Or, you can divide it into individual steps:ant moses-datatypes ant -Dregistry.cache.dir=/tmp/biomobycache moses-datatypes
The last one produces API for generated code. You can find it in docs/APIservices directory.ant -Dregistry.cache.dir=/tmp/biomobycache generate-datatypes ant moses-compile ant moses-docs
The boolean properties use values true or false. Here is how to see what would be generated:
And here are examples of a regular expressions. The first one is case-sensitive (it returns no data type at the moment of writing this), the second is case-insensitive (and produces a dozen of data types):ant -Dregistry.cache.dir=/tmp/biomobycache -Dmoses.nogener=true generate-datatypes
ant -Dregistry.cache.dir=/tmp/biomobycache -Dmoses.filter.dt=sequence generate-datatypes ant -Dregistry.cache.dir=/tmp/biomobycache '-Dmoses.filter.dt=(?i)sequence' generate-datatypes
By default, the skeleton generator creates source code in directory generated/skeletons - and even though this can be changed (see below Ant property src.skeletons or a command-line option -outdir) usually there is no need to do it.
It generates code to the package that reflects (backwards) the service authority name. The names of generated classes are created from the service name with a suffix Skel. For example, a skeleton for a service Mabuhay registered with the authority samples.jmoby.net will be named net.jmoby.samples.MabuhaySkel.
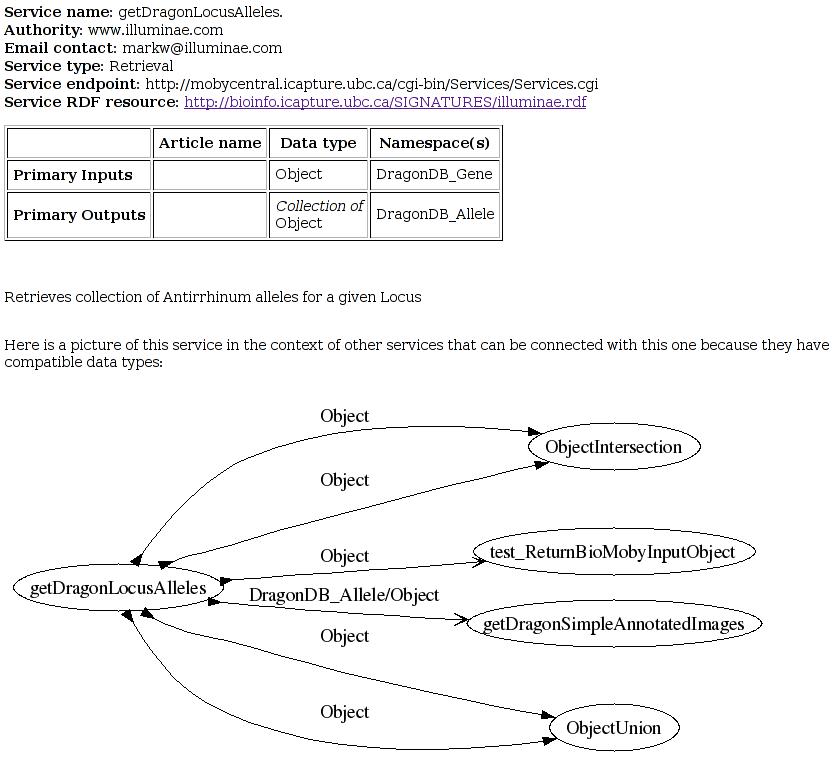
If, by bad luck, a service has a name that does not comply with the rules for Java identifiers, the generator fails (actually, the compilation of the generated code fails). This is not that generator would not be able to make appropriate changes to the name - as it does for data types - but it would not make any sense. Why? Because Biomoby API strictly dictates that the service name is also a method name to be called. So with a bad service name you would have anyway troubles, disregarding if you use generator or not.The generated source code is, similarly to the code for generated data types, annotated (in the API comments) by information taken from the registry. It also shows (unless it is disabled - see options below) a tree of the related services - the services that can provide or consume data to/from the generated skeleton. Here is an example of such generated API:
The same can be achieved by invoking Ant's specialized targets. More about them below. For now let just put the corresponding Ant properties in the parameter tables.build/run/run-generator <options>
But before going to list the options, here is the most frequest error message you get when you wish to generate skeletons:
It says it all: you have to generate data types first before you start generating service skeletons. But - because the slice of bread always falls down on the buttered site - very often you have generated them but either forgot to compile them, or (it happens to me all the time) you removed the compiled classes by calling ant clean.===ERROR=== Class 'org.biomoby.shared.datatypes.MapDataTypes' was not found. It may indicate that you have not generated all Biomoby data types from a Biomoby registry. See http://www.biomoby.org/moby-live/Java/docs/Moses.html for details. If you are a jMoby developer just type: ant moses-datatypes. Or perhaps, they just need to be compiled: ant moses-compile. ===========
Now we can go back to the options and Ant's properties:
| Option/Parameter | Ant's property | Meaning |
|---|---|---|
| -s | generate skeleton (no need to use it if you are using -service or -auth parameter) | |
| -service <reg-expr> | moses.service | What skeletons to generate. Put here service names as regular expression. You can combine this with a regular expression for service authority. |
| -auth <reg-expr> | moses.authority | What skeletons to generate. Put here authority names as regular expression. You can combine this with a regular expression for service names. |
Here is a few typical examples:
Generate skeletons for all services registered by org.irri.iris.www authority:
Generate all skeletons:build/run/run-generator -auth org.irri.iris.www
The program also uses more generic options that are shared with generating data types - see the generic options here.build/run/run-generator -s
More examples, with some generic options. Generate skeletons for services with gene or Gene in name:
Generate services with test in their name, but only from an authority containing icapture:build/run/run-generator -service '(?i)gene'
Using Ant is the same as with data types. Just the target name is now generate-services. The targets for compilation (moses-compile) and for generating API (moses-docs) are the same. Using a cache is again recommended:build/run/run-generator -service '(?i)test' -auth icapture
or everything in one line:ant -Dregistry.cache.dir=/tmp/biomobycache generate-services ant moses-compile ant moses-docs
ant -Dregistry.cache.dir=/tmp/biomobycache moses-services
Obviously, this is the ultimate purpose of the whole Moses
sub-project. To be able to produce a
|
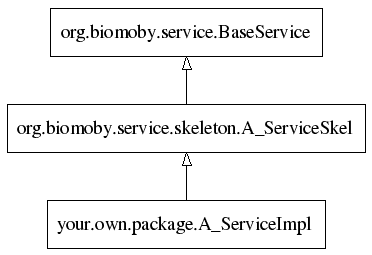
You have to implement the business logic of your service - nobody can help you with that. You start by creating a class that will represent your service. This class should inherit from the generated skeleton. This way it also inherits from the BaseService that has a lot of useful features. Here is how it looks like for a hypothetical A_Service:
In the examples, for the implementation classes, I am using names ending with Impl but that is arbitrary. You can choose whatever name for your class.
In the future, we may find, that the necessity to inherit from a skeleton is a too restrictive factor (because of the only single inheritance in Java). If that happens, we can extend the skeleton generator in order to use a different (interface-based) scenario. Let me know please...For details about the "wrapping" data types used, please look in the section about the Moses parser.
In your class, you have several choices which level you want to control. The bottom-line is that you always have to implement method processIt with the following signature:
public void processIt (MobyJob request,
MobyJob response,
MobyPackage outputContext)
throws MobyException
This method is called once for each job contained in a client
request. A job is a BioMoby query (in a client request), or a result
of one query (in a service response). There can be more queries (jobs)
in one network request to a BioMoby service. If a network request
contains more jobs, also the corresponding service response must
contain the same number of jobs. The request contains data (already parsed into suitable objects, including generated data types), representing one job (i.e. one mobyData tag in a Biomoby speak).
The response is an empty object (except its name that is already filled in - because it must correspond with the same name in the request). Your implementation of this method should fill it with an appropriate response.
The outputContext is a package that will be, at the end, delivered to a client. It is here not to be filled - that is taken care of by some other methods - but you may use it to see how other (previous) jobs have been made. Also, and importantly, you may fill so-called service notes with human-readable messages concerning the whole request, or with errors (or just warnings) concerning either the full request or a particular job.
You may choose to raise an exception if a complete processing should fail. If you do so the client will not get any data back (only an error message). If you wish just to indicate that this particular job failed you have to add an exception to the outputContext. For example:
if (something happened) {
outputContext.addException
(ServiceException.error ("This is an error"),
request);
} else {
// normal proceeding
}
There are more ways how to create an instance of a
ServiceException - see its API for
details. This is all you need to use in most cases.
But you can choose to have control on a higher level - to be called just once for all jobs. In that case you have to override method (and provide an empty implementation of the previous processIt method):
public void processIt(MobyPackage mobyInput,
MobyPackage mobyOutput)
throws MobyException
Here mobyInput contains all data coming from a client, and
mobyOutput is an empty package that will go later to the
client - your implementation should fill it with a response. There are other useful methods to use - check the API of the BaseService for details.
Now, when you know what method to implement, is time to see what access you have to the data sent by a client, and what means you have to produce your own data. You will be always checking the API of the generated skeleton, and the API of the used data types, of course - but here are few basic rules that can make your investigation more efficient:
There are always two ways to get/set data. You can use methods of a general object MobyJob, or you can use methods from generated sketeltons.
The methods in MobyJob either get data by name (meaning by an article name, and only if it does not exist the data type name is used), or they get data from the first Simple Biomoby type - which often is the only one. For example:
public void processIt (MobyJob request,
MobyJob response,
MobyPackage outputContext)
throws MobyException {
// get the first Simple data
System.out.println (request.getData());
// get the Simple data that have article name "Sequence"
System.out.println (request.getData ("Sequence"));
// get the Simple data that have an article name "abc" or none at all,
// AND it is of the type "Regex"
System.out.println (request.getData ("abc", "Regex"));
// get the first Simple that matches the data type "Regex"
System.out.println (request.getData ("", "Regex"));
// get the first Collection
System.out.println (printCol (response.getDataSet()));
// get the Collection data that have article name "Sequences"
System.out.println (printCol (response.getDataSet ("Sequences")));
// get the Collection data that have an article name "abc" or none at all,
// AND its elements are of the type "Regex"
System.out.println (printCol (response.getDataSet ("abc", "Regex")));
// get the first Collection whose elements match the data type "Regex"
System.out.println (printCol (response.getDataSet ("", "Regex")));
}
private String printCol (MobyObject[] col) {
if (col == null) return "null";
if (col.length == 0) return "empty";
return col[0].toString();
}
The MobyJob's getMethod(article-name,
data-type-name) has the following built-in behaviour:
The generated skeletons allows to work directly with the generated data types. They have methids that have already in their names corresponding article names and data types names. For example:
public void processIt (MobyJob request,
MobyJob response,
MobyPackage outputContext)
throws MobyException {
Regex input = get_language (request);
if (input == null) return;
simple_key_value_pair[] output = doBusiness (input);
set_helloSet (response, output) ;
}
Note that in the example above the language is an article
name of a Biomoby Simple, Regex is its data type, Also the
simple_key_value_pair is a data type name. The hello
is an article name of an output collection. The full examples of some Bimoby services are in jMoby in src/samples directory.
{kind=link}